
Abstract
Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine- tuning or implicit reward signals like CLIP scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
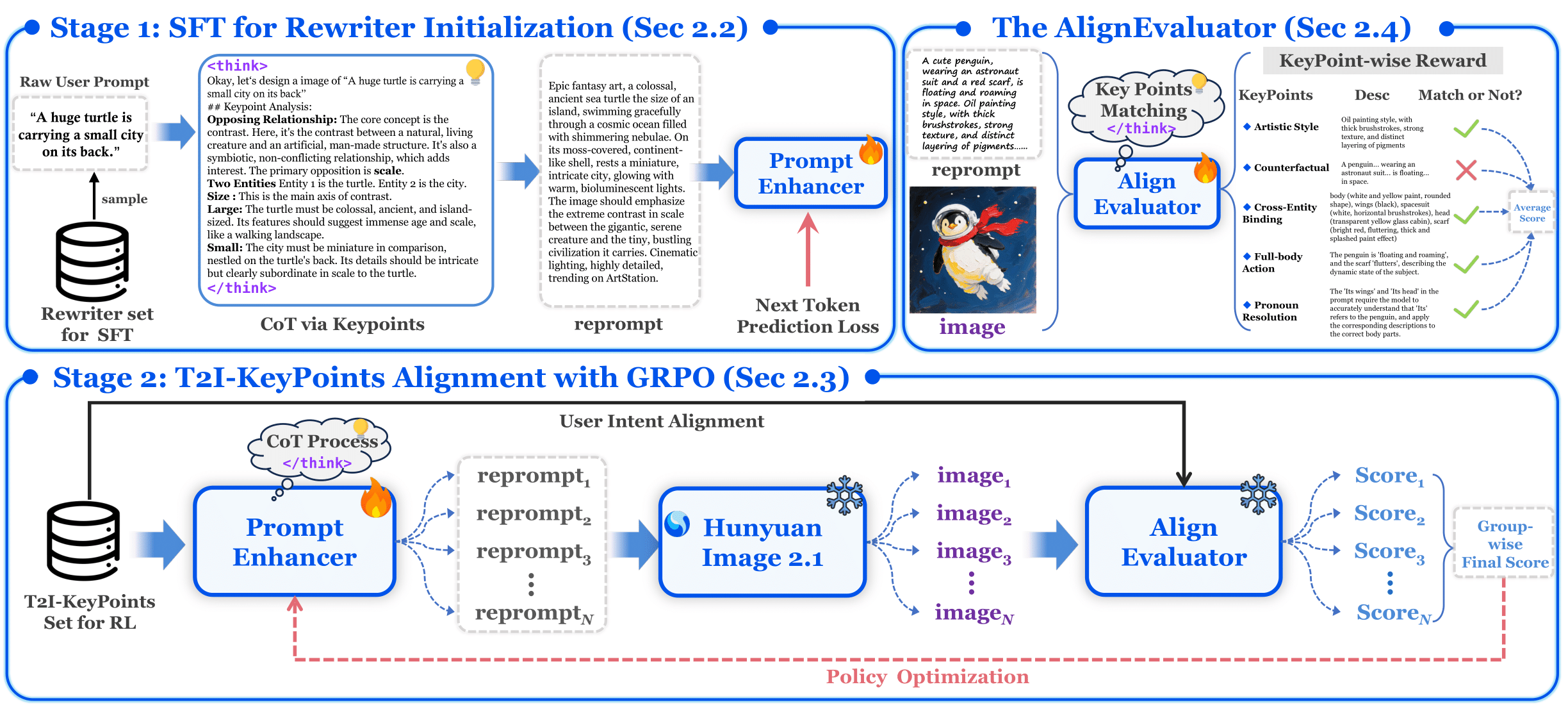
Methodology
Stage 1: SFT for Rewriter
Initialization (Sec 2.2). The CoT Rewriter is first initialized through Supervised Fine-Tuning (SFT).
In this stage, the model learns to generate structured, chain-of-thought style responses by training
on (user prompt, reprompt) pairs using a standard next-token prediction loss. This provides a
strong starting point for the subsequent alignment phase.
Stage 2: Policy Alignment with GRPO
(Sec 2.3). The initialized rewriter is then refined using a reinforcement learning loop based on
Generative Reward-based Policy Optimization.
For a given prompt, the CoT Rewriter generates multiple candidate reprompts. These are fed into a frozen T2I model
to produce images. The AlignEvaluator (Sec 2.4) then assesses each (image, prompt) pair and
provides a scalar reward.
This reward signal optimizes the rewriter's policy, steering it toward generating prompts that maximize the alignment between the image and the user's intent.
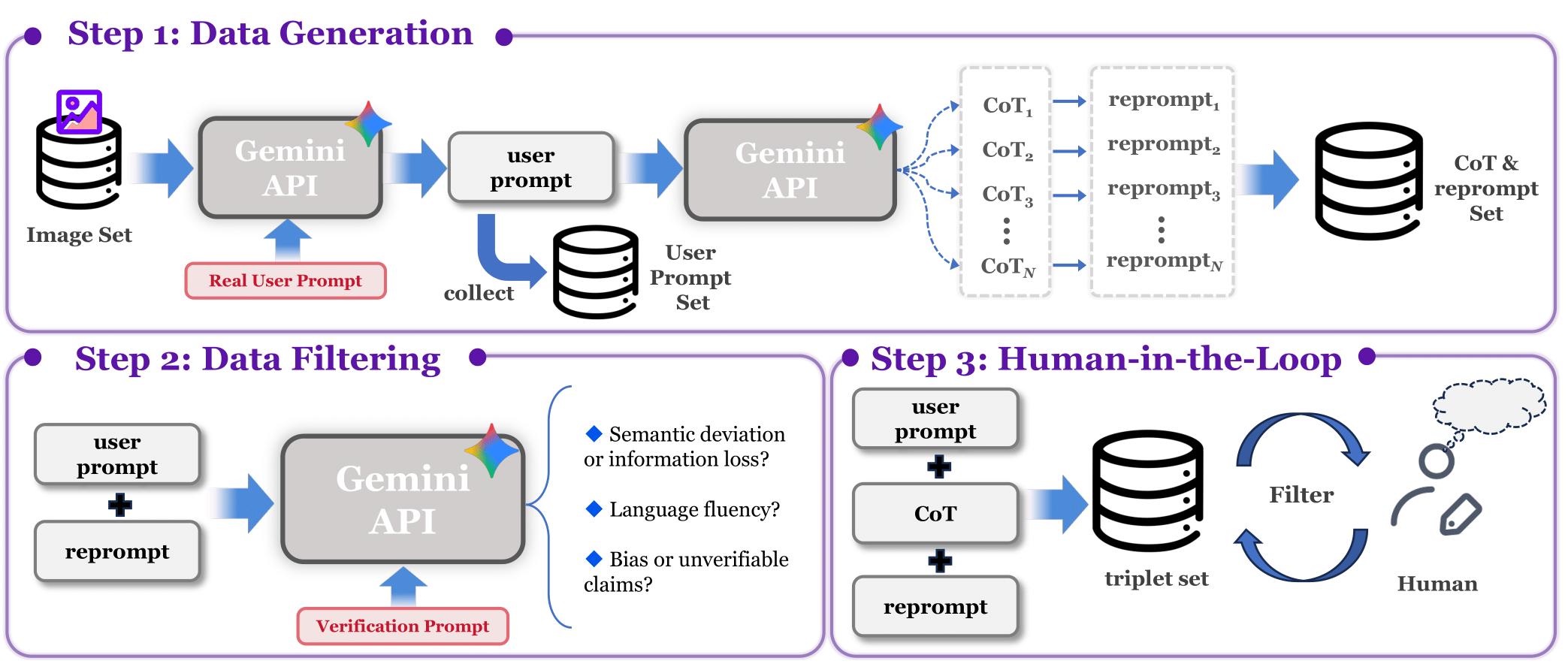
Data Pipeline
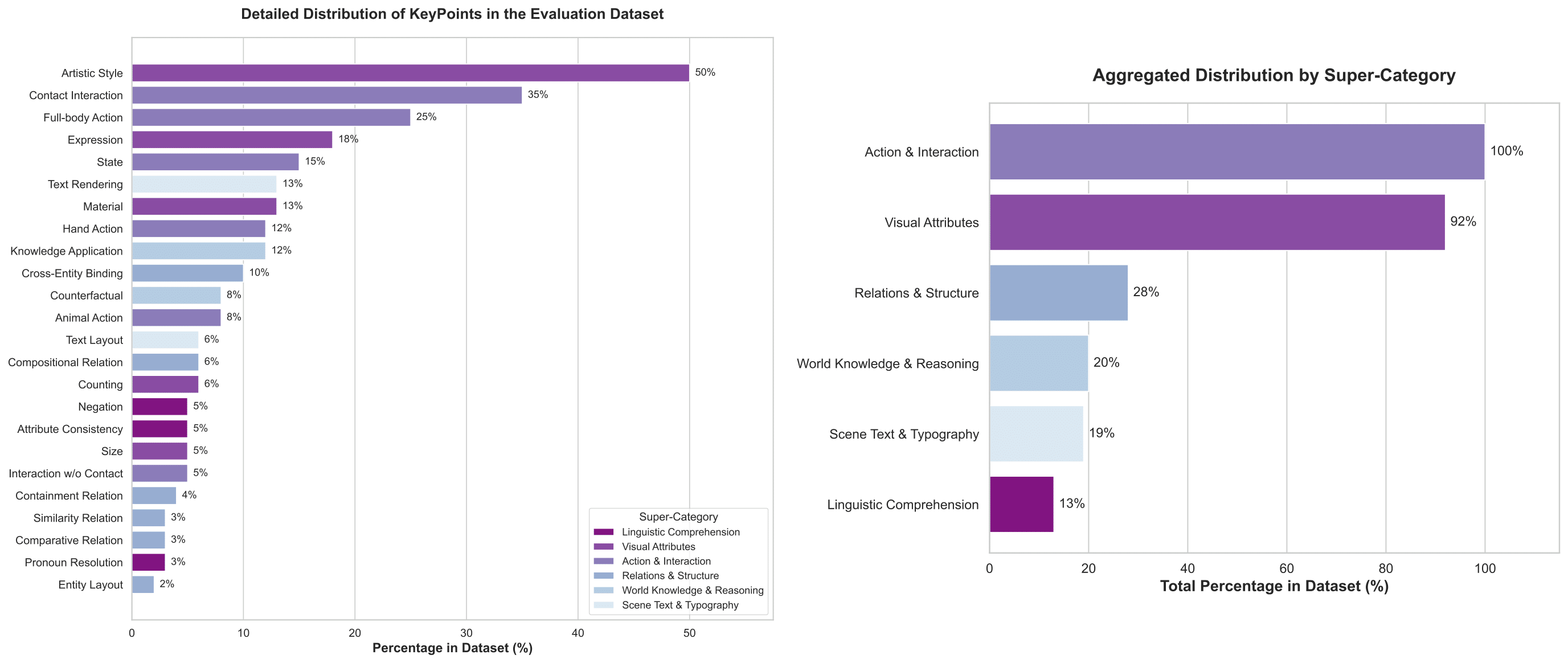
Data Analysis
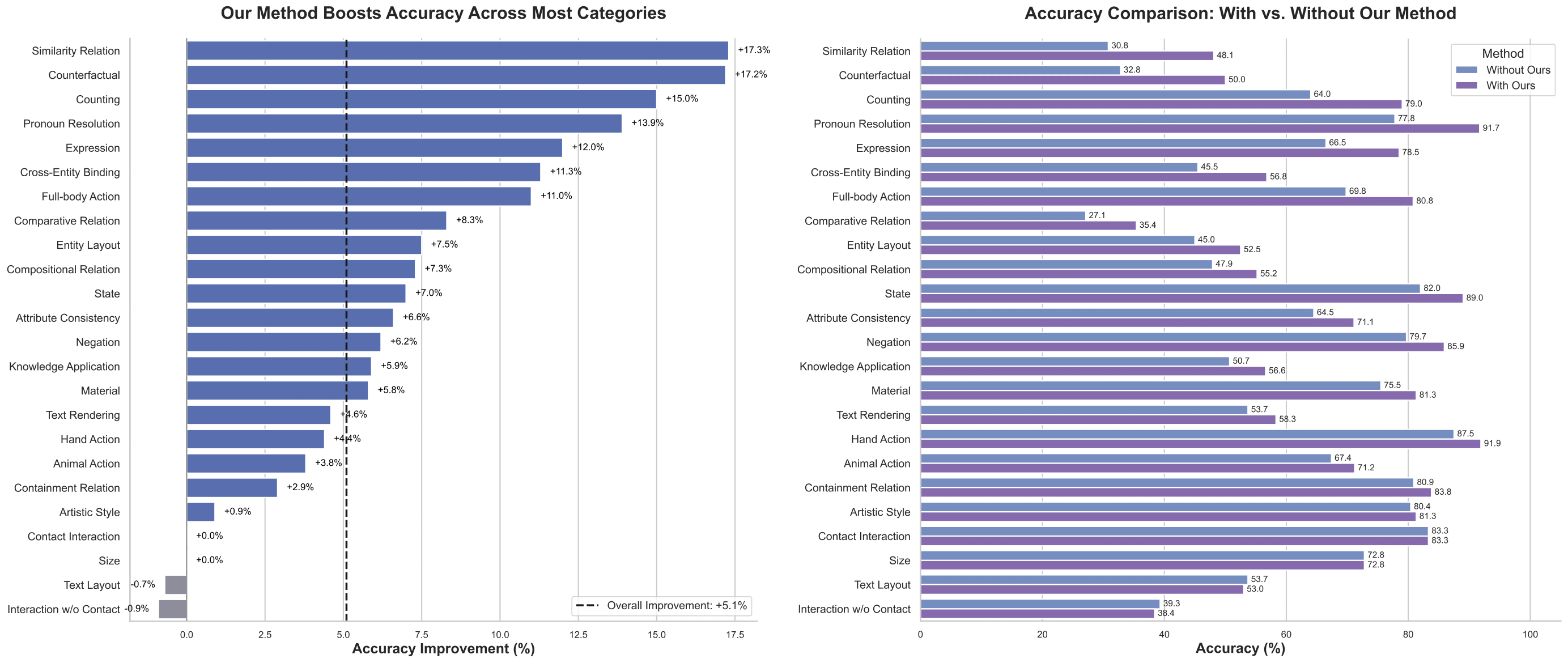
Experimental Results

Quantitative Evaluation
Citation
@article{promptenhancer2025,
title={PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting},
author={Linqing Wang and Ximing Xing and Yiji Cheng and Zhiyuan Zhao and Donghao Li and Tiankai Hang and Zhenxi Li and Jiale Tao and Qixun Wang and Ruihuang Li and Comi Chen and Xin Li and Mingrui Wu and Xinchi Deng and Chunyu Wang and Qinglin Lu},
booktitle={arXiv preprint:2509.04545},
year={2025}
}
Acknowledgements
We would like to thank Kai Song, and ZhengKai Jiang for their valuable inputs and suggestions.
We are open-sourcing the PromptEnhancer-7B version, which includes a larger model, dataset, benchmark, and the reward model AlignEvaluator. These will be released progressively. Additionally, the PromptEnhancer series for multimodal applications, such as image-to-image, text-to-video, image-to-video, will be coming soon.
我们将开源PromptEnhancer-7B版本,涵盖更大参数的PromptEnhancer模型、数据集、基准测试以及奖励模型AlignEvaluator等内容,后续将逐步开源。同时,针对图生图、文生视频、图生视频等多模态应用的PromptEnhancer系列也将在不久后发布。